

 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
假设真实模型是,但你估计了。如果你利用Y在X=-3、-2、-1、0、1、2、3处的观测并估计了“不正确”的模型,
假设真实模型是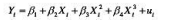 ,但你估计了
,但你估计了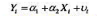 。如果你利用Y在X=-3、-2、-1、0、1、2、3处的观测并估计了“不正确”的模型,这些估计值将出现什么偏误?
。如果你利用Y在X=-3、-2、-1、0、1、2、3处的观测并估计了“不正确”的模型,这些估计值将出现什么偏误?
 答案
答案
查看答案
 请输入或粘贴题目内容
搜题
请输入或粘贴题目内容
搜题
 拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
假设真实模型是,但你估计了。如果你利用Y在X=-3、-2、-1、0、1、2、3处的观测并估计了“不正确”的模型,这些估计值将出现什么偏误?
答案
 更多“假设真实模型是,但你估计了。如果你利用Y在X=-3、-2、-1、0、1、2、3处的观测并估计了“不正确”的模型,”相关的问题
更多“假设真实模型是,但你估计了。如果你利用Y在X=-3、-2、-1、0、1、2、3处的观测并估计了“不正确”的模型,”相关的问题
第1题
利用APPLE.RAW中的数据。这些电话调查数据是为了得到(假想的)“环保”苹果需求。调查者向每个家庭都(随机地)介绍了正常苹果和环保苹果的一组价格,并询问他们愿意购买每种苹果的磅数。
(i)对于样本中的660个家庭,有多少家庭报告称在预定价格上不愿意购买环保苹果?
(ii)变量ecolbs看上去在严格正值上具有连续分布吗?你的回答对ecolbs托宾模型的适当性有何含义?
(iii)以ecoprc、regprc、famic和hhsize作为解释变量,估计一个托宾模型。哪些变量在1%的水平上显著。
(iv)faminc和hhsize联合显著吗?
(v)第(iii)部分中价格变量系数的符号与你的预期一致吗?请解释。
(vi)令β1和β2为ecoprc和regprc的系数,相对一个双侧备择假设,检验假设H0:-β1=β2。报告检验的p值。(如果你的回归软件不能很容易地计算这种检验,你可能还要参考教材4.4节
(vii)对样本中的所有观测求E(ecolbslx)的估计值[见方程(17.25)],称之为ecolbsi。最大和最小拟合值是多少?
(viii)计算ecolbs,和ecolbsi之相关系数的平方。
(ix)现在,利用第(iii)部分中同样的解释变量,估计ecolbs的一个线性模型。为什么OLS估计值比托宾估计值小那么多?从拟合优度来看,托宾模型比线性模型更好吗?
(x)评价如下命题:“由于托宾模型的R,如此之小,所以估计的价格效应可能是不一致的。”
第2题
。一个简单的模型为
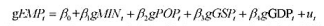
其中, MINt 是最低真实工资, POPt是18~25岁之间的人口, GSPt 是州生产总值, GDPt 是美国国内生产总值。前缀g表示从t-1年到1年的增长率,它通常用对数之差来近似计算。
(i)如果我们担心该州会部分基于一些(对我们来说)无法观测但对年轻人就业有影响的因素来选择最低工资, 那么OLS估计将存在什么问题?
(ii)令US MINt 为美国最低工资, 它也是一个真实量。你认为gUS MINt 与ut 不相关吗?
(iii)按照法律, 各州的最低工资都必须不低于全国最低工资。解释这为什么使得gUS MINt 成为gM INt 的一个潜在Ⅳ。
第3题
本题利用JTRAIN3.RAW中的数据。
(i)估计简单回归模型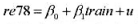 并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
(ii)现在使用真实劳动工资的变化cre=re 78-re 75作为因变量。(由于我们假定1975年之前没有工作培训,所以我们没有必要对train进行差分。也就是说,如果我们定义ctrain=train 78-train75, 那么,由于train75=0,所以ctran=train78。)现在,培训的估计影响有多大?讨论它与第(i)部分估计值的比较。
(iii)利用通常的OLS标准误和异方差-稳健标准误求培训效应的95%置信区间,并描述你的结论。
第4题
利用INTQRT.RAW中的数据。
在教材例18.7中,我们估计了六月期国库券持有期收益率的一个误差修正模型,其中三月期国库券持有期收益率的一阶滞后为解释变量。我们假定在方程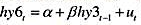 中的协整参数为1。现在,添加Δhy3t-1的先导变化Δhy3t、同期变化Δhy3t-1和滞后变化Δhy3t-2。即估计方程
中的协整参数为1。现在,添加Δhy3t-1的先导变化Δhy3t、同期变化Δhy3t-1和滞后变化Δhy3t-2。即估计方程
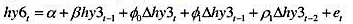
并用方程形式报告结果。相对于双侧备择假设,检验H:β=1.假定方程中已经有了足够多的先导和滞后,使得{hy3t-1}在这个方程中是严格外生的,我们不必担心序列相关。
(ii)在教材(18.39)中的误差修正模型中,添加{hy3t-1}和{hy6t-2-hy3t-3}。这两项是联合显著的吗?你认为怎样才是适当的误差修正模型?
第5题
是一个表示拥有个人计算机的二值变量):
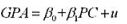
(i)为什么PC可能与u相关?
(ii)解释为什么PC可能与父母的年收入相关。这是否意味着父母的收入作为PC的IV还不错?为什么?
(iii)假设四年前学校为大约一半的学生提供了购买计算机的资助,而获得资助的学生是随机挑选的。仔细解释你如何利用这一信息为PC构造一个工具变量。
第6题
利用WAGEPAN.RAW中的数据。
(i)考虑非观测效应模型
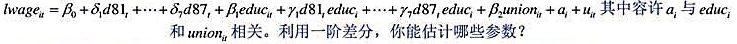
(ii)用FD估计第(i)部分中的方程,并检验不同时期的教育回报没有变化的原假设。
(iii)利用一个足够稳健的检验,也就是容许FD误差Δuir中存在任何形式的异方差和序列相关的检验,检验第(ii)部分中的假设。你的结论有变化吗?
(iv)现在,容许是否加入工会的差别(与受教育水平一起)在不同时期有所变化,用FD估计这个方程。1980年加入工会与不加入工会的估计工资差别是多少?1987年呢?这个差别在统计上显著吗?
(v)检验工会关系差别在不同时期没有发生变化的原假设,并根据你对第(iv)部分的回答讨论你的结论。
第7题
本题利用WAGEPAN.RAW中的数据。
(i)考虑非观测效应模型

(iv)现在,容许是否加入工会的差别(与受教育水平一起)在不同时期有所变化,用FD估计这个方程。1980年加入工会与不加入工会的估计工资差别是多少?1987年呢?这个差别在统计上显著吗?
(v)检验工会关系差别在不同时期没有发生变化的虚拟假设,并根据你对第(iv)部分的回答讨论你的结论。
第8题
下面这个模型是比德尔和哈默梅什(BiddleandHamermesh,1990)所用多元回归模型的一个简化版本,原模型研究睡眠时间和工作时间之间的取舍,并考察影响睡眠的其他因素:
sleep=β0+β1totwrk+β2educ+β3age+u
其中,sleep和totwrk都以分钟/周为单位,而educ和age则以年为单位。(也可参见计算机练习C3。)
(i)如果成年人为工作而放弃睡眠,β1的符号是什么?
(ii)你认为β2和β3的符号应该是什么?
(iii)利用SLEEP75.RAW中的数据,估计出来的方程是
sleep=3638.25-0.148totwrk-11.13educ+2.20age
n=706,R2=0.113.
如果有人一周多工作5个小时,预计sleep会减少多少分钟?这是一个很大的舍弃吗?
(iv)讨论educ的估计系数的符号和大小。
(v)你能说totwrk,educ和age解释了sleep的大部分波动吗?还有什么其他因素可能影响花在睡眠上的时间?它们与totwrk可能相关吗?
第9题
本题使用JTRAIN.RAW中的数据。
(i)考虑简单回归模型
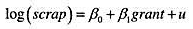
其中,scrap表示企业的废品率,grant表示是否得到工作培训津贴的一个虚拟变量。你能想到u中的无法观测因素可能会与grant相关的原因吗?
(ii)利用1988年的数据估计这个简单的回归模型。(你应该有54个观测。)得到工作培训津贴显著地降低了企业的废品率吗?
(iii)现在增加一个解释变量log(scrap87)。这将如何改变grant的估计影响?解释grant的系数。相对于单侧备择假设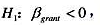 它在5%的显著性水平上统计显著吗?
它在5%的显著性水平上统计显著吗?
(iv)相对双侧备择假设,检验log(scrapg)的参数为1的虚拟假设。报告检验的P值。
(v)利用异方差-稳健标准误,重复第(iii)步和第(iv)步,并简要讨论任何明显的差异。
第10题
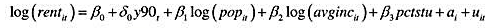
其中pop是城市人口,avginc是平均收入,而petstu是学生人口占城市人口的百分数(按学年计算)。
(i)用混合OLS估计方程并按标准方式报告结果。你如何理解1990年虚拟变量的估计值?你得到βpctstu是多少?
(ii)你在第(i)部分中报告的标准误是否真实?请解释。
(iii)现在,将方程差分并用OLS估计。把你对βpctstu的估计值和第(ii)部分进行比较。学生人口的相对规模对房租有影响吗?
(iv)对第(ii)部分中的一阶差分方程求异方差-稳健的标准误。这是否改变了你的结论?























